Home
Free Trial
Home
Free Trial
Read More
Content
Filter
10 results found
Featured
AI in PCB Design: What Works Today and What Doesn’t
Featured
How to Place Parts from a Component Database in OrCAD X CIP
Featured
Why DDR and PCIe Cause EMI and How to Stop It
Featured
Evaluating EMI Risk in PCB Design Before Hardware Testing
Featured
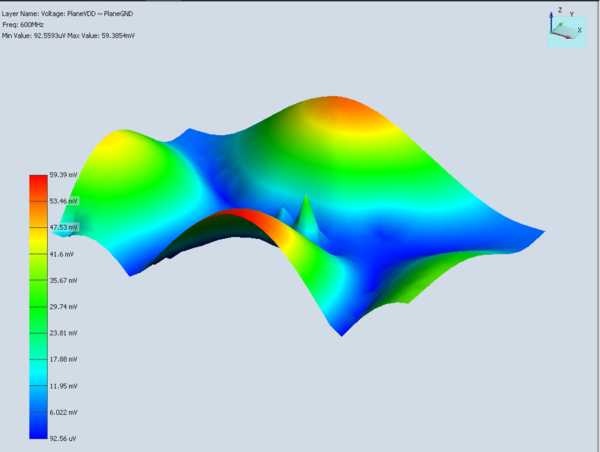
Power Distribution Noise and Its Impact on EMI in PCB Design
Featured
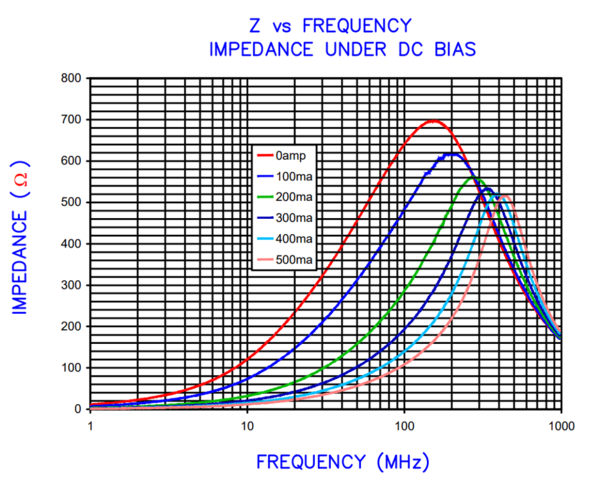
When Do Ferrite Beads Help or Hurt EMI Performance in PCB Designs?
Featured
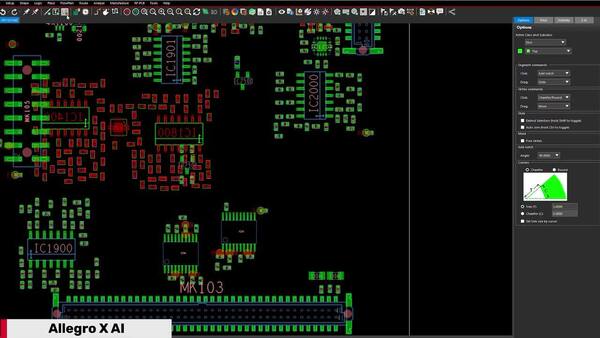
Danfoss Uses Cadence Allegro X AI to Amplify PCB Design for Energy Efficiency
Featured
How to Optimize the Electronic New Part Introduction Process for PCB Design
Featured
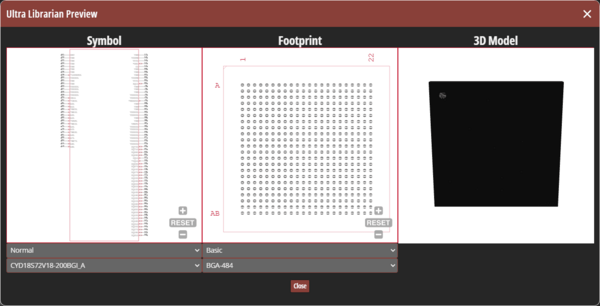
How to Use Verified Symbols, Footprints, and 3D Models for New Components in OrCAD X CIP
Featured
EMI Reduction Techniques for Switching Power Supply PCB Layouts
Featured
Products
None
Allegro X PCB
(2)
OrCAD X
(1)
Allegro X AI
(1)
Sigrity X Aurora
(2)
Solutions
None
Artificial Intelligence
(1)
Library Authoring & Management
(1)
PCB Layout
(5)
Simulation & Analysis
(5)